
For decades, the pursuit of general-purpose robotics has oscillated between two paths. On one side are brittle pipelines—hand-engineered systems that deliver reliable performance in narrow domains but were never designed for generality. On the other are large foundation models—ambitious in scope and showing promise for broad capabilities, yet still data-hungry, opaque, and difficult to transfer in robotics settings. Neither path alone offers the adaptability and extensibility that true general-purpose robotics demands.
Today, we are unveiling our blueprint for pursuing general-purpose robot intelligence through agentic architectures.
Rather than relying solely on end-to-end models, we argue that progress lies in modular AI skills: specialized models for perception, planning, and control that each solve part of the problem well. This is precisely where LLM-based agentic systems shine. The real challenge is not just building these modules, but finding ways to compose them into coherent behaviors. That assembly requires agency—the ability to reason about goals, select tools, and adapt from experience.
This shift has already reshaped software, where agents generate code, manage toolchains, and orchestrate workflows by invoking the right tools at the right time. The stakes for robotics are even higher: here, agents must integrate perception, action, and memory in the open world—demanding diverse skill libraries, scalable infrastructure, and standardized deployment.
We are reframing the robot intelligence problem as one of skill identification, composition, and orchestration.
Skills as the building blocks
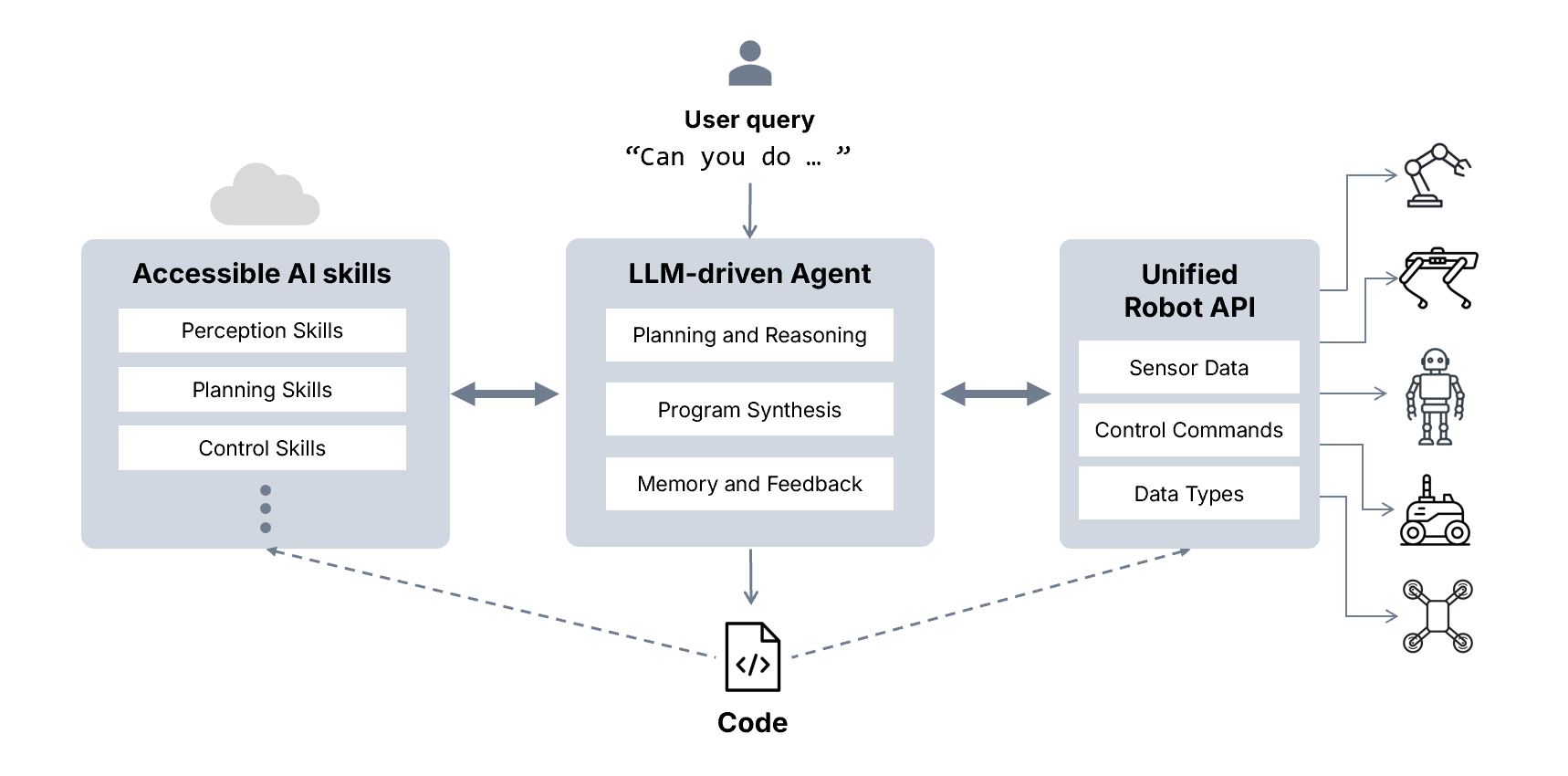
GRID builds on a large repertoire of robot AI skills—modular units of perception, planning, or control. These skills span a wide spectrum: allowing robots to detect objects, figure out grasp points, identify obstacles, and understand scenes, and much more.
In addition to AI skills, we also treat low-level robot capabilities as part of the skill library.
A central design principle of GRID is the unification of such robot skills into consistent primitives per form factor, e.g. for accessing images, sending velocity commands, or executing trajectories. This eliminates SDK fragmentation across robots and provides a clean abstraction layer for reasoning especially from an agent’s point of view. With a unified interface represented in pure Python, agents can rapidly move from simulation to reality, or from one OEM’s robot to another, without significant rewrites. This allows GRID to work with any robot form factor with ease.
Agents for Orchestration
GRID’s agentic layer turns these skills into scalable intelligence. GRID’s agents operate in two complementary modes:
- In tool-calling mode, GRID directly invokes skills step by step, grounding future decisions on previous outputs and its own commonsense reasoning. This lets the agent dynamically adapt mid-task—monitoring outcomes and deciding on-the-fly which tool to call next.
- When well encapsulated skills are not readily available, GRID operates in code generation mode, where it creates larger programs that create new skills or orchestrate skills with glue logic into complex routines.
We standardize the interfaces of such skills and make them composition-ready through the Model Context Protocol (MCP). Our MCP servers expose each skill in a structured, LLM-friendly format. They publish the API signature, usage examples, and operational constraints, so skills can be discovered, validated, and composed with others. This design ensures that agents see skills and robot interfaces as structured, documented tools. Every skill is explicit code, its inputs and outputs observable, and reusable across contexts.
The outputs in either case are auditable, debuggable Python programs — far more interpretable than a black-box policy. GRID’s agents also provide step-by-step plans before moving on to code generation, allowing human feedback to guide the process.
For example, when a UR5 arm is asked to pick and place an object, GRID composes a script invoking segmentation, grasping, and motion planning tools in sequence. Once validated, that composition can be stored as a new skill, which can be reused zero-shot in progressively harder contexts, like cleaning up a table, or sorting objects by category.
The skill library is therefore self-expanding: every new composition can be another building block.
Using LLMs as the orchestrators means we have access to their powerful reasoning skills at any time. For example, they can easily figure out if a task is infeasible, and how to make it feasible. When tasked with something like “sort these objects by category”, they can perceive and reason about the objects through vision, and use it to guide their decision making.

We apply these principles of modularity and extensibility to have GRID play robot chess: combining board state recognition, grasping, motion planning, and reasoning into a closed loop. Unlike foundation models such as vision-language-action models which take significant effort to extend and fine-tune for a new task, an agentic system can simply encode new tools and compose them into behavior.
One architecture spans every robot
Our agentic framework applies seamlessly across manipulators, quadrupeds, humanoids, wheeled robots, and drones.
- Create pick and place capabilities for a UR5 arm and extend that to longer horizon tasks like cleaning up a table, sorting objects based on category, and more.
- Have a Unitree G1 humanoid bring a bag of chips to a person.
- Navigate in an office space with a Unitree Go2 quadruped until a yellow caution sign was found.
- Use an indoor drone to track and follow a moving target.
Across these embodiments, most behaviors emerged zero-shot: the system recombined existing skills in new contexts without any retraining. This illustrates how agentic architectures can generalize across platforms and tasks, providing a pathway toward more unified and extensible robotic solutions.
Modularity is what makes this generality real.
For cases where a skill might not exist, GRID allows agents to invoke simulations also as callable tools. GRID agents demonstrated the creation of a safe navigation routine for a wheeled robot by launching simulation, proposing code, understanding failures, and refining until collisions stopped. Such a behavior can then be saved and reused across tasks or improved further for more operational domains.
Robots do not have to be static executors; they should be systems that compose and extend their own intelligence.
In robotics, agents gain a unique advantage through simulation: a sandbox where they can invent, test, and scale new capabilities. Just as swarms of agents are being used to tackle open-ended problems like mathematics by exploring thousands of solution paths in parallel, agents in robotics can leverage simulation to explore and validate new capabilities, making adaptation both scalable and safe. Similar to how code or response correctness can be used as a signal for LLM post-training, verifiability from simulation can be a useful construct for making LLMs more robotics ready.
Elasticity and unification for scale via accessible AI skills
For agents to be effective, they require access to a broad library of perception, planning, and control skills that can be combined, swapped, or updated as tasks evolve. Sequential orchestration and parallel composition are particularly demanding, often requiring multiple models to execute concurrently. To support this, skills are best hosted on remote accelerators—whether in the cloud or in dedicated on-premise clusters—where diversity and scale can be sustained independently of robot hardware. This architecture enables agents to compose models in parallel, swap capabilities seamlessly, and propagate updates instantly across a fleet.
With sufficiently optimized communication protocols, almost all skills can be served remotely at practical latency, leaving only reflexive low-level and safety behaviors on-device. This balance allows intelligence to scale across robots, embodiments, and tasks without being bottlenecked by local hardware.
Memory and Human-Like Cognition
Human cognition relies on memory not just to store information, but to encode experiences, compress them into useful abstractions, recall them in context, and reflect on them to improve future behavior. This is what gives our actions continuity and adaptability. For robots to operate in the open world, they need the same: a way to ground reasoning in what they have seen and done, and to refine their competence over time.
GRID provides this continuity through layered memory.
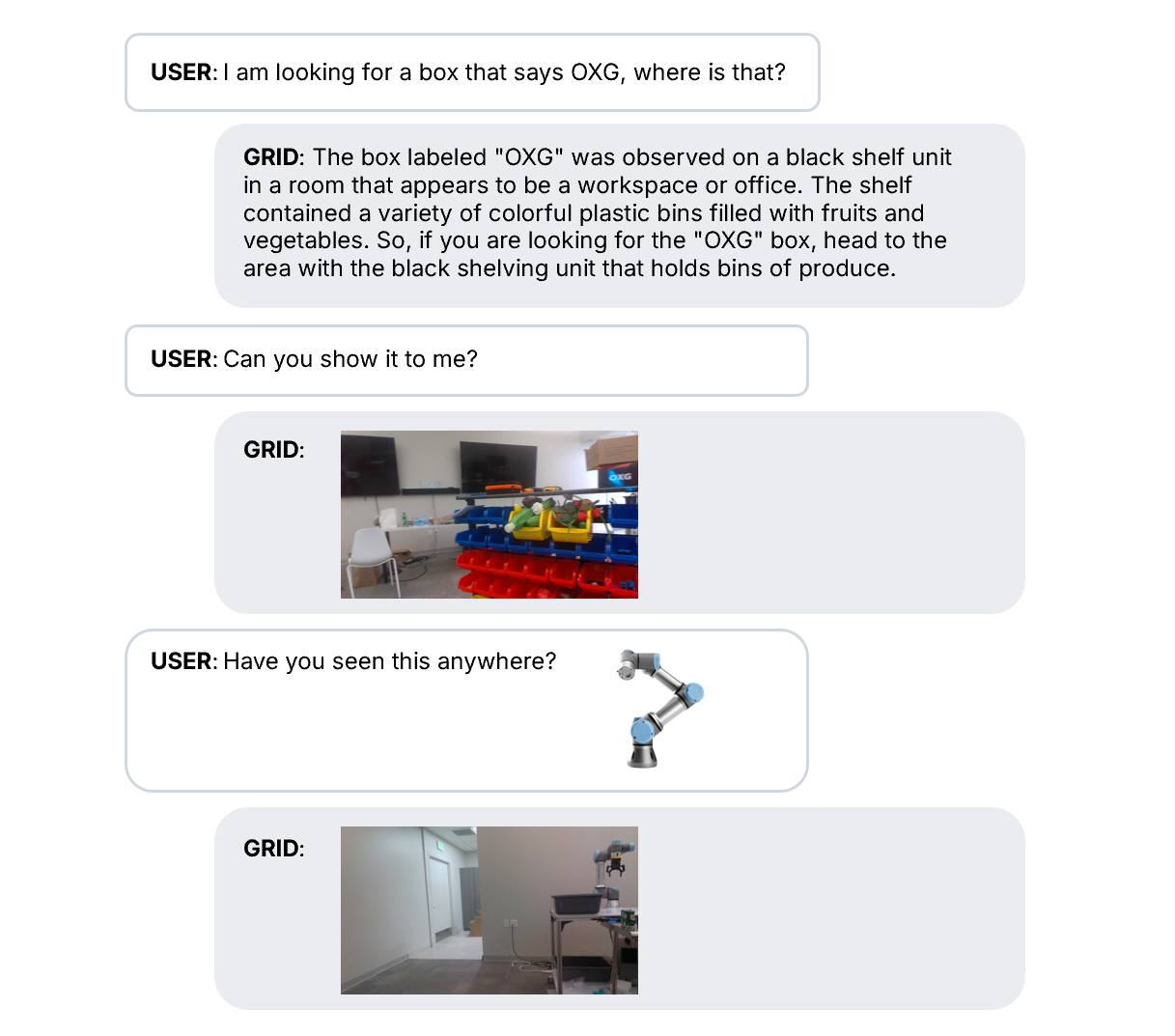
- Observational memory records the world in an agent-friendly way as semantic snapshots through textual captions, object-centric image embeddings, and more. Our robots can answer questions with grounded evidence, receive images as input and identify similar locations or objects, or just converse casually about a space.
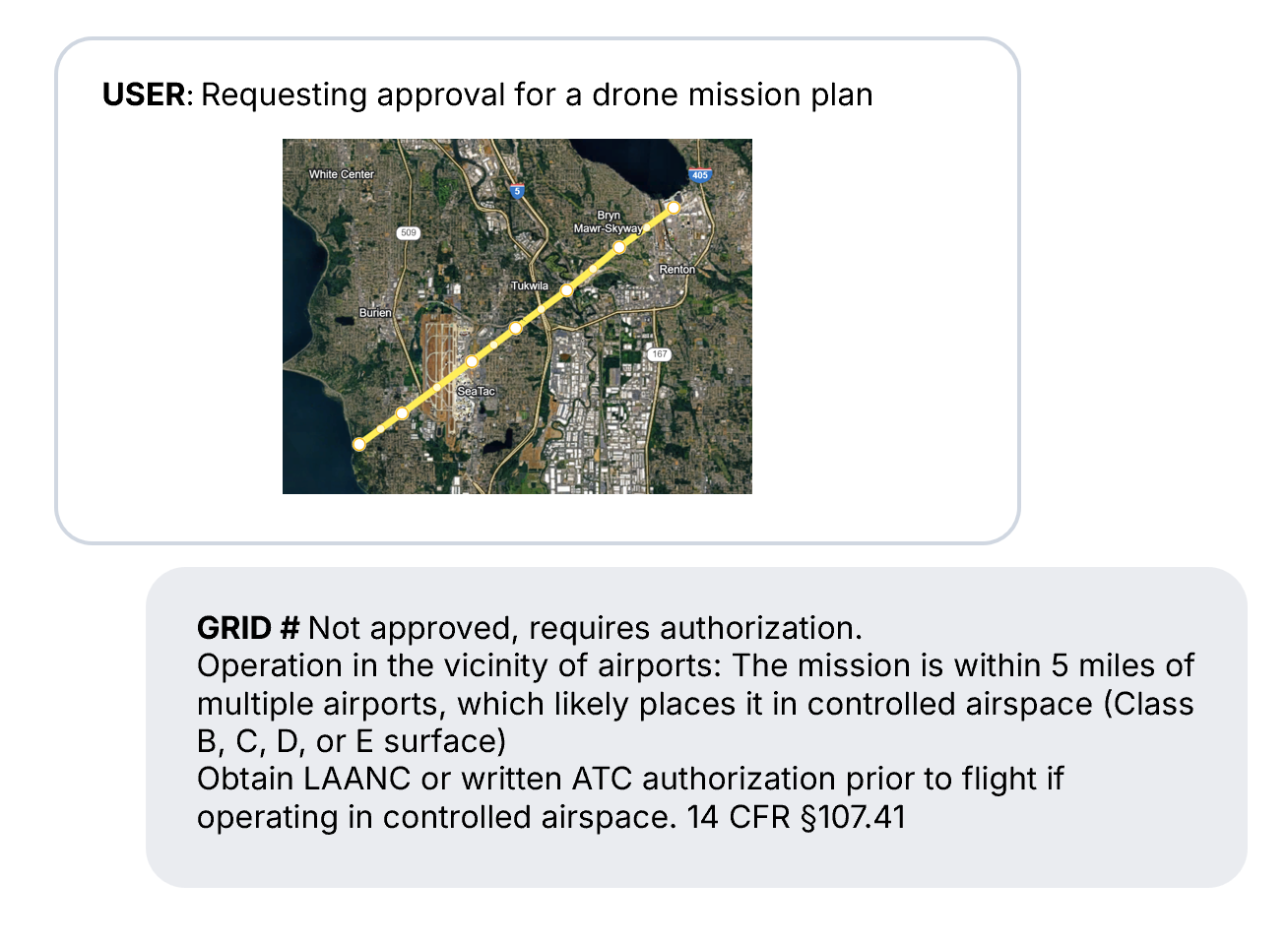
- Operational memory tracks what the agent attempted, which skills were invoked, previous examples, and how execution unfolded, with the potential to convert each run into reusable competence. This can also encode external knowledge such as environmental or task specific guidelines. For example, we gave our agent access to the FAA Part 107 guidelines for small UAS piloting, and it was able to ground its decision making in these rules.
The experience this enables is strikingly human-like.
You can ask a robot what it is doing, why it made a decision, or request alternatives, and it can explain transparently. That seamless back-and-forth transforms the robot into a collaborator rather than an inscrutable machine.
Toward General Robotics
Taken together, these principles— accessible AI skills, agentic composition, and memory-driven cognition—change how we think about building general-purpose robots. We treat intelligence as something that emerges from reasoning, composition, and experience. When robots are able to call from a variety of skills, refine them or adapt them, and use memory to adjust their behaviors, they become far more adaptable and transparent.
The age of the general-purpose robot will be defined by agents that can reason, converse, compose, remember, and learn continuously—and by architectures designed to make those abilities concrete and measurable.
Read our detailed study in our paper: https://genrobo.github.io/Agentic-Robotics/paper.pdf
Experience GRID: https://www.generalrobotics.company/schedule-a-demo
If you find this work useful, you can cite it as:
@article{vemprala2025agentic,
title = {Agentic Architectures for Robotics: Design Principles and Model Abilities},
author = {Vemprala, Sai and Norris, Griffin and Rishi, Brandon and Anthireddy, Pranay and
Vuppala, Sai Satvik and Lovekin, Arthur and Garg, Mayank and Katara, Pushkal and
Qiu, Tianshuang and Chin, Nathaniel and Shah, Preet and Punjwani, Saif and Bhagat, Sarthak
and Huang, Jonathan and Chen, Shuhang and Kapoor, Ashish},
year = {2025},
note = {Available at \url{https://genrobo.github.io/Agentic-Robotics/paper.pdf}}
}